Viewing posts by Aysun Akarsu
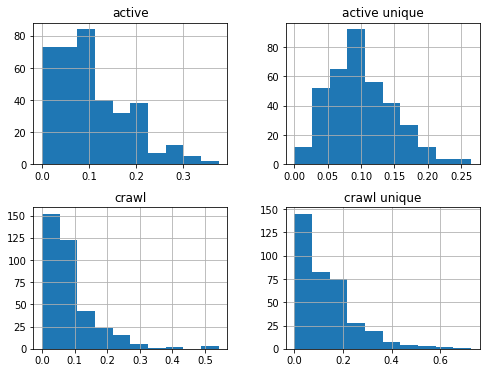
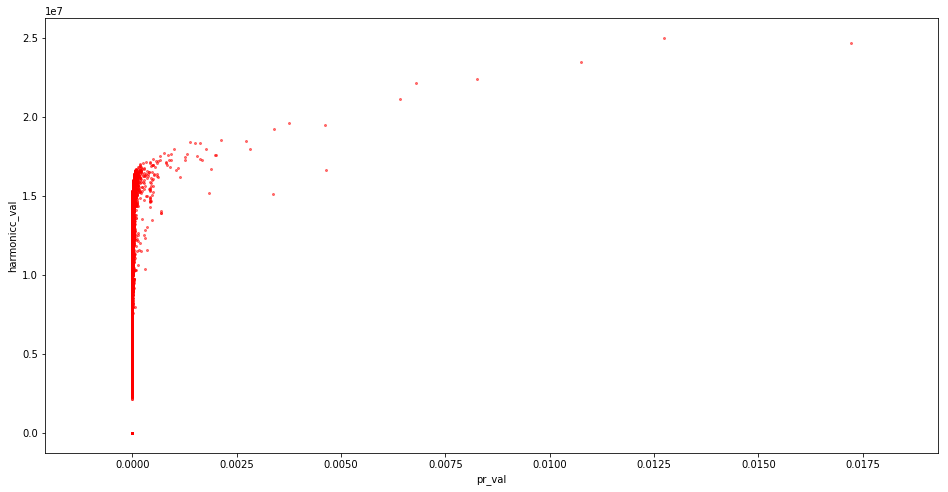
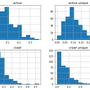
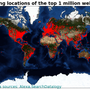
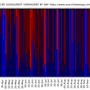
87 million domains pagerank
87 million domains pagerank and harmonic centrality
When we search "Common Crawl" on google, knowledge graph states that "Common Crawl is a nonprofit 501 organization that crawls the web and freely provides its archives and datasets to the public. Common Crawl's web archive consists of petabytes of data collected since 2011. It completes crawls generally every month. Common Crawl was founded by Gil Elbaz."
read more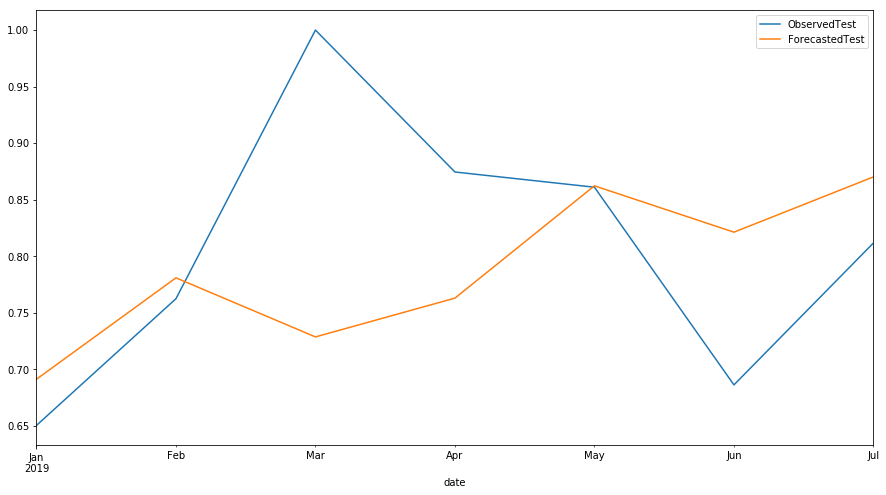
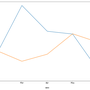
SEO Forecasting
SEO Forecasting
This blog post is published first on 2018-10-22 and updated on 2023-03-07.
read more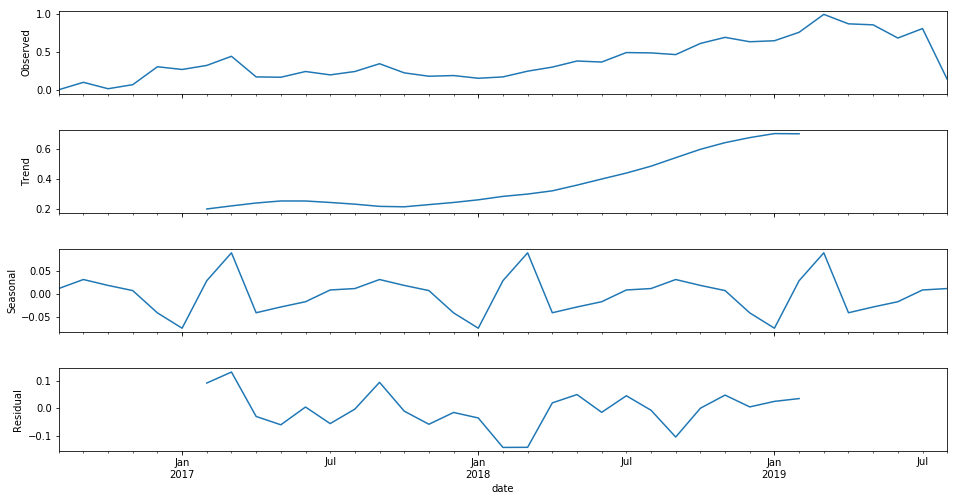
SEO data analysis
SEO data analysis
This blog post is published first on 2018-10-18 and updated on 2019-08-20.
read more
BrightonSEO conference
This article was first published on 15/09/2017 and updated on 15/09/2019
read more
HTTP2 on top sites
HTTP2
This article was first published on 06/08/2016 and updated on 04/07/2018.
read more

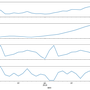
Desktop & mobile performances
Homepage speed of top half million sites
Httparchive is a non profit organization tracking websites. It may remind you Internet Archive which collects and permanently stores the Web's digitized content however its aim is different. This organization is not interested in collecting and storing the digitized content but rather interested in recording how digitized content is constructed and served.
read more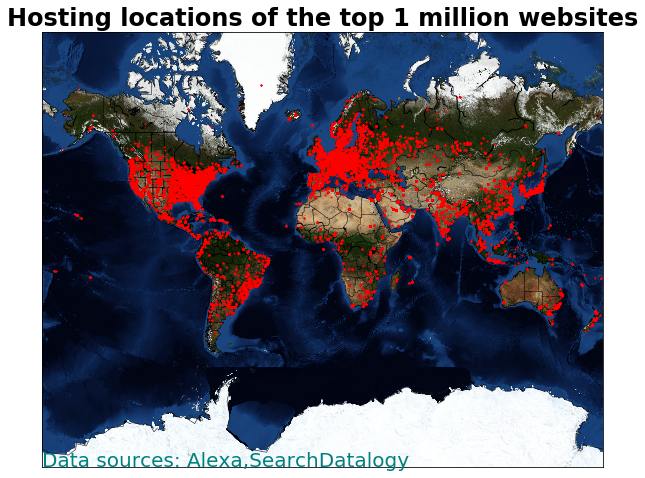
Alexa top 1 million sites
Alexa top 1 million sites data analysis
Which continents, countries belong Alexa's top 1 million sites in the world?
Have you ever wondered which countries, continents belong top 1 million sites in the world?
read more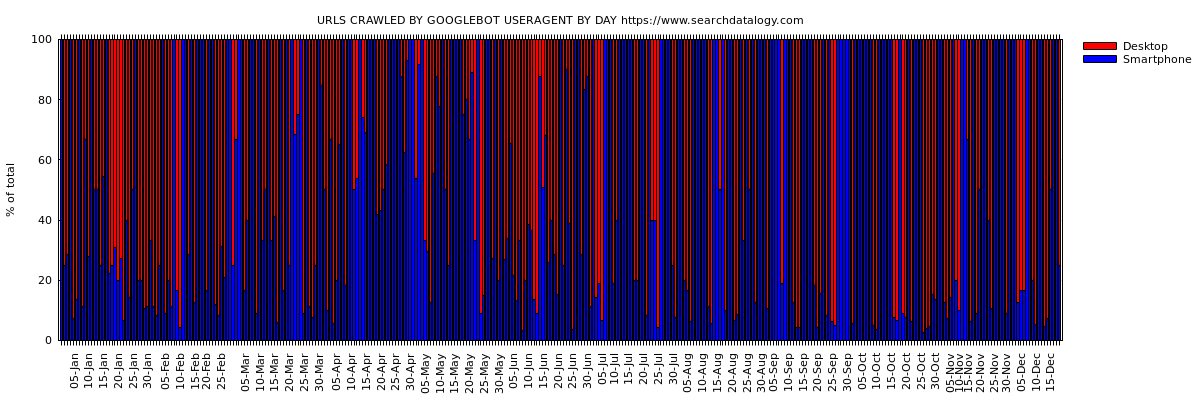
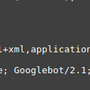
Is my site in google's mobile first index?
Is my site in google's mobile-first index?
Your site's web server logs will answer the question
As we know few sites have already moved to google’s mobile-first index.
read more